

Donald Sturgeon (2015-2017 An Wang Postdoctoral Fellow) explains how to build a digital humanities course.
Digital methods have revolutionized many fields of study, not only by offering more efficient ways of conducting research and teaching along traditional lines, but also by opening up entirely new directions and research questions which would have been impractical or even impossible to pursue prior to the digital age.
This digital revolution offers new and exciting opportunities for many humanities subjects — including Chinese studies. Through the use of computer software, digital techniques make possible large-scale studies of volumes of material which would once have been entirely impractical to study in depth due to the time and manual effort required to assemble and process the source materials. Even more excitingly, they offer the opportunity to apply sophisticated statistical techniques — often already extensively developed in other fields due to applications in science and industry — to give new insight and understanding into important humanities questions.
Against this background, in 2016 as part of the Fairbank Center’s Digital China Initiative and with the support of the Department of East Asian Languages and Cultures, a graduate-level course titled Digital Methods for Chinese Studies was offered for the first time to the Harvard community.
This course aimed to introduce students working primarily in Chinese studies to practical programming skills and digital humanities techniques which they would be able to apply to their own research in future. While assuming no technical background in programming or digital techniques, over the course of the semester students obtained hands-on experience with modern software techniques for analysis and visualization of textual materials. This began with a practical introduction to programming using Python, which served as the backbone of the rest of course by giving students practical experience with creating the software “glue” typically needed to bind together different techniques and sources of real-world data in order to perform meaningful research using digital methods.
While not a programming course and therefore not attempting to comprehensively cover an entire programming language, the programming element was fundamental to the overall goal of enabling students to carry out useful research using digital techniques independently, both as part of the course and in their future work. By allowing students to learn how to transform large amounts of data from whatever form it may currently be available in — such as web pages, academic databases, and other varied collections of primary source data — into forms to which useful analysis can be applied, the programming component of the course also made it possible for each student to work directly with materials relevant to his or her own research instead of simply working with examples chosen by the instructor.
[Digital Humanities] offer the opportunity to apply sophisticated statistical techniques to give new insight and understanding into important humanities questions.
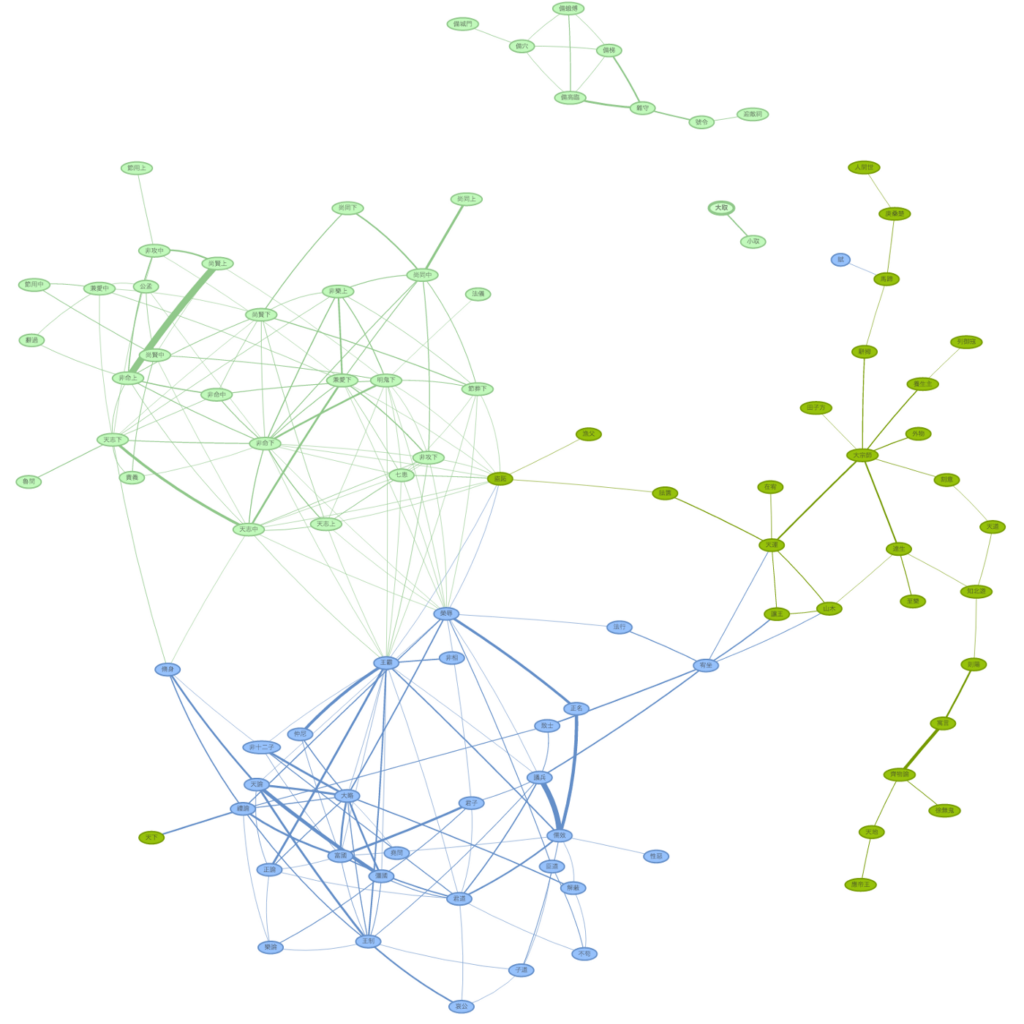
At the same time as introducing basic programming, the course also covered an ambitious range of digital methods with a focus on methods applicable to the study of textual materials. These began with simple but highly flexible techniques such as regular expressions, a standard mechanism for specifying and identifying patterns in textual data — and one particularly well-suited to Chinese language materials, given the latter’s high per-character semantic content. The course then moved on to more specialized and advanced techniques, starting with practical methods for harvesting large amounts of data automatically from websites and online repositories — this was one of the ways in which students obtained the data needed for their research projects. Other topics covered included automatic identification of textual similarity and text reuse, network visualization of relational data, distant reading using topic modeling, and finally principal component analysis and machine learning.
Given the nature of the material and goals of the course, the format was highly interactive, and each of the topics covered was introduced with practical examples and applied by all students in class to appropriate data. Each weekly session typically began with an introduction of new concepts introduced and an overview of the techniques themselves, followed by a hands-on lab session in which students applied these techniques in practice using real data. The final session of the course consisted entirely of student presentations, in which each student introduced their own data, methods, results, and analysis based on the application of techniques covered during the course to their own research materials. There were many excellent presentations covering a wide variety of topics; to give an indication of what students were able to achieve over the course of a semester, below are concrete examples taken from two of the student projects from the Spring 2017 course.
Student Projects from the Digital Methods Course
1. Chinese stories of talented scholars and beauties
This project by Wenchu Zhu focused on a genre of pre-modern novels traditionally grouped together as “Stories of talented scholars and beauties (才子佳人小說)”. The complete text of the 22 titles chosen for the project were first fetched using Python by Application Programming Interface (API) from the Chinese Text Project database. The texts chosen intentionally included several works for which authorship and dating are unknown or disputed, and one goal of the project was to identify and interpret possible evidence for the authorship of these texts on the basis of a comparison of their content and style to those of other texts included in the study.
Wenchu applied a variety of techniques in her project, including using similarity measures to compare how vocabulary usage varied across the texts, and using Support Vector Machines (SVMs, one type of machine learning algorithm) to train a statistical model to accurately distinguish between texts written in various different styles based on analysis of their content, also evaluating its reliability against known cases. She then applied a similar technique using SVMs to build a statistical model aiming to distinguish between novels composed in different time periods based on word usage. This model was trained and evaluated using data from texts with known authorship to demonstrate the reliability of its results, then applied to texts with questionable authorship to give predictions about their likely origin.
Her project also used Principal Component Analysis (PCA) to investigate stylistic variation among texts in the study. PCA can be used with textual materials to visualize how word frequencies vary in different pieces of writing. In order to look at stylistic variation, Wenchu looked first at frequencies of grammatical particles (虛詞) only, as these — unlike frequencies of content terms (實詞) — might be expected to remain consistent within a particular style of writing even as subject matter changes. PCA was applied to frequency data extracted from every chapter of every text in the study to give a two-dimensional visualization of variance of grammatical particle usage within and between texts:
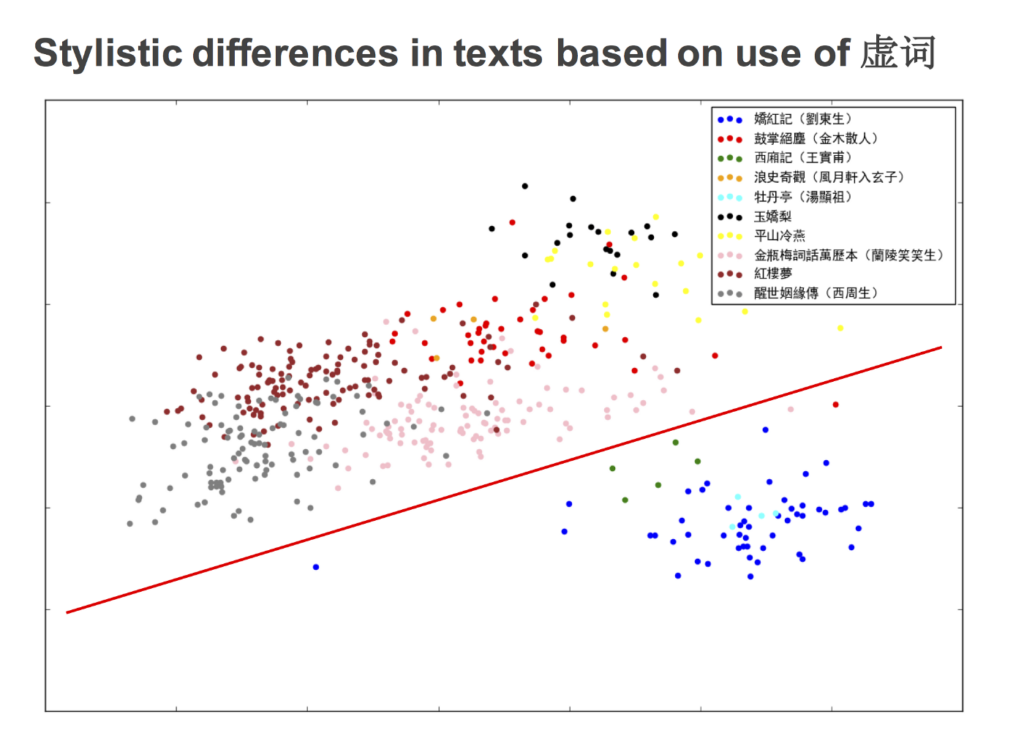
In the above plot, each dot represents one section of a text, with the text to which the section belongs represented by the color indicated in the legend. Dots appearing closer together correspond to chapters with similar rates of usage of grammatical particles as a whole, with those further apart having greater degree of variation. The red line is an interpretative annotation highlighting the clear difference in style between the 嬌紅記, 西廂記, and 牡丹亭 (represented by dark blue, green, and light blue respectively) and the remainder of the texts.
The same technique was then reapplied with a different purpose: to investigate differences of content rather than style among these texts. In this case, the frequencies analyzed were not those of particles, but instead words connected with morality or value judgment — terms such as 禮, 義, 道, 善, 惡, etc. This resulted in a visualization corresponding to variation in use of these terms in the texts considered:
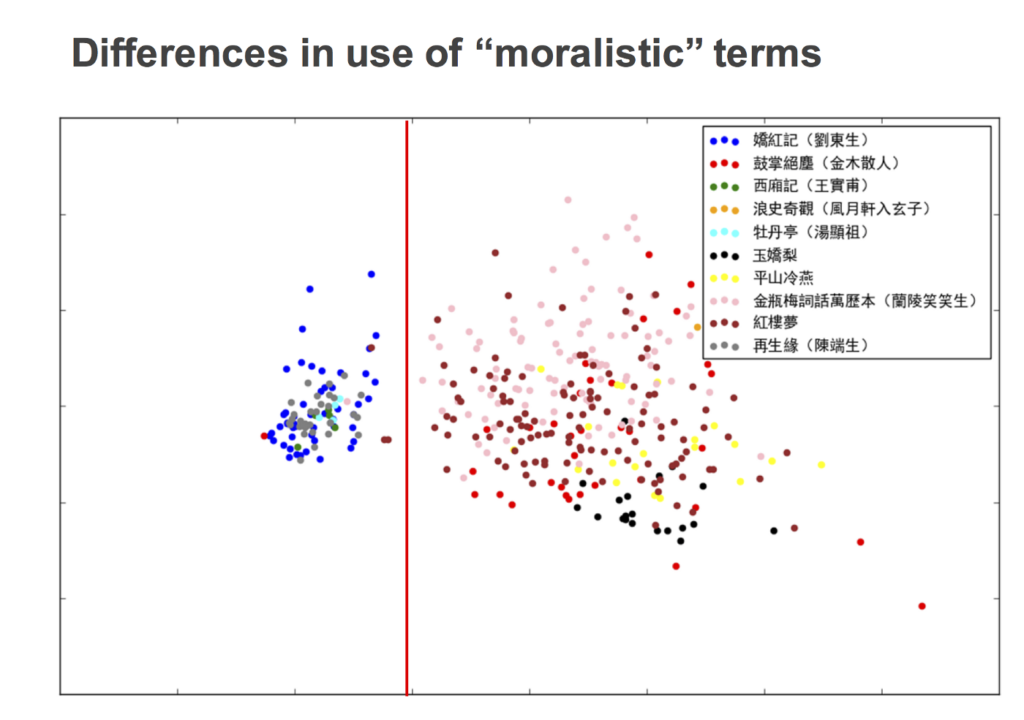
The red line, again added interpretatively by Wenchu, indicates how in this body of texts, usage of the selected terms varies starkly between texts whose frequency patterns appear solely on the left and those appearing exclusively on the right — with a small number of notable exceptions warranting manual investigation.
2. Political reform in contemporary China
This project by Jialu Li focused on more recent sources, and investigated political elites and their reform agendas in contemporary China, by analyzing 305 central government reports from 1977 to 2016 obtained from the 行政体制综合 section of the 中国改革信息库 (reformdata.org) website. These were fetched automatically using a Python program, meaning large amounts of data could be fetched without a corresponding large amount of manual effort; Jialu also plans to further develop the project in the future using even larger datasets.
Jialu then used topic modeling to facilitate distant reading of the documents obtained. Topic modeling is a statistical technique which can be used to enable interpretative insights into large bodies of textual material, by automatically analyzing patterns of word frequency and co-occurrence across a set of documents. Topic modeling results in a list of “topics” — in the context of topic modeling, a “topic” is a set of words — as well as, for each document, an account of which of these “topics” is associated with the document. Real-world natural language documents tend to use certain words when discussing certain subjects, and consequently these words also tend to co-occur repeatedly in different documents — for instance, newspaper articles discussing China are more likely to include words such “Beijing”, “Chinese Communist Party”, or “Asia” than typical documents unrelated to China, even though these words may appear in some unrelated documents. As a result, given large enough numbers of documents it becomes possible to identify statistically groups of words which frequently co-occur in the same types of document, and at the same time, which of these various groups of words appear (and to what extent) in any given document in the set. The “topics” generated are statistically motivated, and there is no guarantee that they will be meaningful beyond the statistical properties which underwrite them; however, in conjunction with human interpretation they can be useful in analyzing trends in large bodies of textual material by making visible patterns which otherwise could not be seen without painstaking document-by-document close reading.
In Jialu’s project, a topic model was first created from the set of documents obtained, and then meaningful topics identified and given interpretative labels such as “改革试点与简政放权 (pilot reform and delegation of power)” or “对国务院进行依法监督 (legal supervision of the State Council)”, describing what political subjects the “topics” represented by those word associations tended to be discussing. This interpretation of the topics was then used together with the data from the topic model itself about how topics relate to documents, as well as data about which documents were produced in which years, to map out changes in topic over time, such as in the following chart:
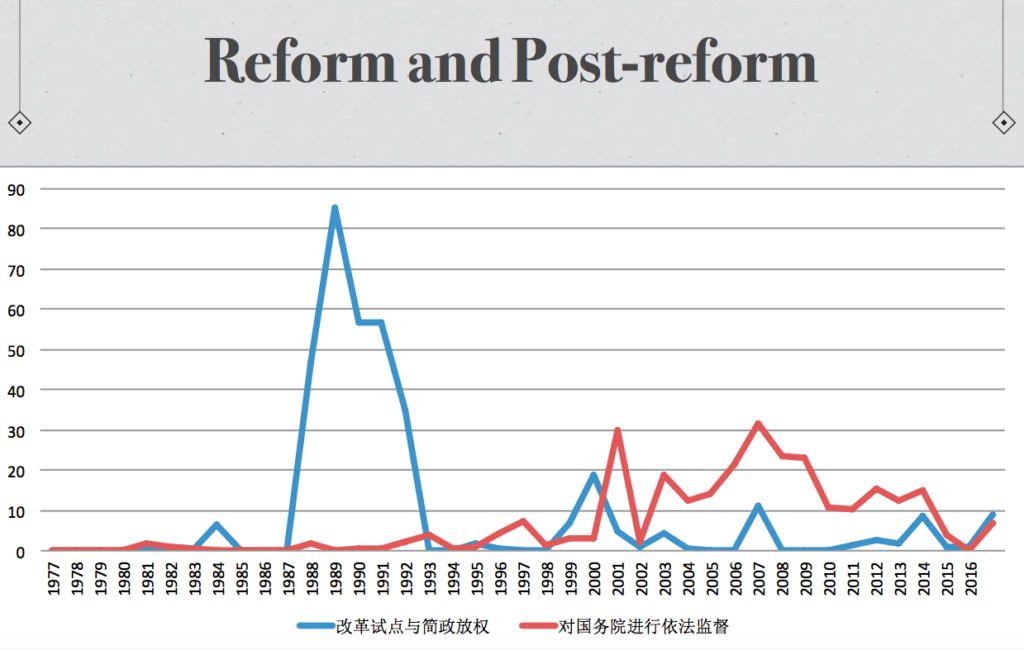
The blue peak centered around 1989 indicates a period during which administrative reform stood out as a central topic in the documents studied, trailing off sharply in the early 1990s; the wider and flatter red peak centering around 2007 a more cautious — but longer-lived — interest in legal supervision of the State Council. The topic model produced also makes it possible to quickly identify within the large set of documents which particular documents in any year are closely related to any given topic, and thus charts such as the one above provide not only an at-a-glance summary of aggregate data, but also a map with which to find documents related to particular topics at particular points in time.
Donald Sturgeon is a former An Wang Postdoctoral Fellow at the Fairbank Center for Chinese Studies. He is the founder of the Chinese Text Project, an online open-access digital library that makes pre-modern Chinese texts available to readers and researchers all around the world.