

“Norbu ketaka,” Tibetan for “cleansing jewel,” refers to a gem said to possess the magical power to purify murky waters. The name encapsulates this project’s mission: to cleanse obscure and error-laden texts, to restore digitized Tibetan manuscripts’ pristine clarity and the wisdom of the Buddha.
An East Asian Languages and Civilizations (EALC) doctoral student has pioneered a remarkable project that uses artificial intelligence technology as a “cleansing jewel” to clean up ancient Tibetan manuscripts whose texts were garbled in the digitization process.
“Norbu Ketaka: A Neural Spelling Correction Model Built on Google Optical Character-Read Tibetan Manuscripts” was made possible through a grant from the Harvard China Fund awarded to Leonard W.J. van der Kuijp, Professor of Tibetan and Himalayan Studies in the EALC Department at Harvard University and Chair of the Committee on Inner Asia and Altaic Studies.
Professor van der Kuijp, who is also a co-founder of the Buddhist Digital Resource Center (BDRC), and Queenie Luo, an EALC doctoral student whose research focuses on leveraging computational techniques to study early Chinese society, guided the “Norbu Ketaka” project from January 2022 to August 2023. The work was completed with the help of researchers at Sichuan University’s Center for Tibetan Studies.
Luo led the project, which processed one million pages of Tibetan texts using a combination of computer vision and natural language processing (NLP) algorithms. The Norbu Ketaka Project is the first of its kind to establish an efficient, AI-powered framework to correct and annotate Tibetan texts at scale.

The project is especially important because it solves a challenge in using AI to process Tibetan manuscripts: the Tibetan language is “low-resourced,” meaning that it has less data available for training AI systems. Following its completion, the team donated the collection to the BDRC as an asset for researchers involved in the fields of Tibetan and Buddhist studies, as well as the larger NLP and AI communities.
The results are “groundbreaking,” said Jann Ronis, Executive Director of the BDRC. “No one had ever applied this methodology to the post-processing of Tibetan texts before,” he adds. “On behalf of BDRC, I’m very grateful to Ms. Luo, Professor van der Kuijp, and the Harvard China Fund Research Grant, and the research assistants at Sichuan University” for sharing all of the data that they amassed at the conclusion of the project with the field of Tibetan AI, where it has “served as a foundation for further developments in Optical Character Recognition and language models, including machine translation.”
A state-of-the-art pipeline for data-cleaning
One of the main collaborators that Luo and her team worked with on Norbu Ketaka was Kurt Keutzer, Professor of Electrical Engineering and Computer Science at the University of California, Berkeley. He provided technical advice and assisted with updating Google’s Tibetan Optical Character Recognition (OCR) system. “For all the press regarding today’s Large Language Models (LLMs), the ‘little secret’ is that there is, in fact, very little diversity in the underlying Neural Net model architectures of these LLMs,” Professor Keutzer explains. “The real difference in the performance of these models is due to their training data and training regimen. Thus, those creating pipelines of high-quality training data are the real heroes of today’s GenAI revolution.”
Professor Keutzer is quick to identify the Norbu Ketaka project as one such hero: “Norbu Ketaka has brought state-of-the-art data aggregation and cleaning techniques to Tibetan literature. Both the development of the data-cleaning pipeline and the resulting one million pages of cleaned Tibetan texts are significant contributions to the field of Tibetan studies.”
Inside the Project Pipeline
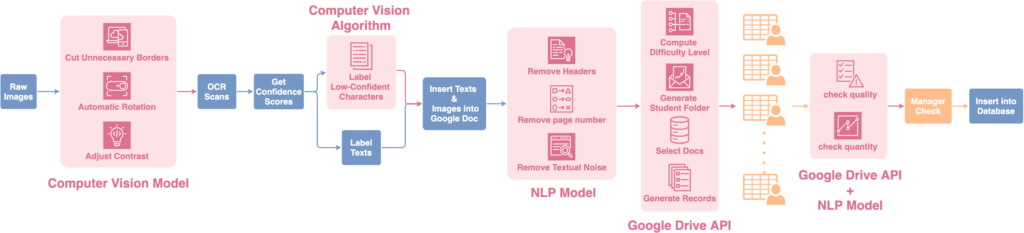
How did they do it? Luo designed a pipeline (pictured) for the Norbu Ketaka project that broke the work up into discrete stages. The first stage required that the raw images of Classical Tibetan manuscripts be pre-processed using three AI vision models. These models had to do the following: (1) rotate images; (2) remove borders; and (3) adjust contrast. The models significantly improved the quality of the images and, consequently, reduced Google OCR errors by up to 50%.
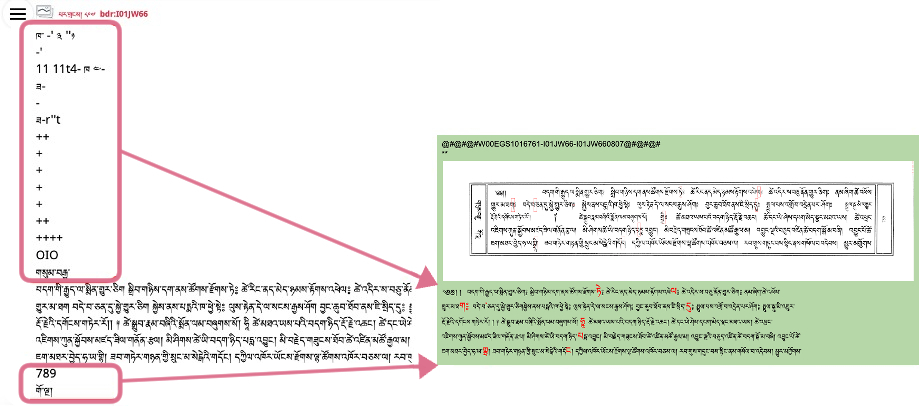
After Google OCR produced each of the recognized syllables and corresponding confidence scores, these were extracted as an indicator of syllable identification accuracy. The images and corresponding texts were then labeled with their accuracy scores to help annotators focus on words with a high probability of error. Luo also integrated a Tibetan language model to auto-correct low-level spelling mistakes, which accounted for an average of 30% of total errors. Finally, the pre-cleaned and labeled data was inserted into Google Docs via its API. The resulting integration of AI vision models into the Tibetan language model led to an 80% to 90% average in character recognition errors across various collections of Tibetan texts.

For the next stage, a team of 40 researchers—experts in ancient Tibetan scripts—at Sichuan University annotated the pre-cleaned texts to correct the remaining high-level errors in the transcripts. However, dispatching 12,000 documents across 40 annotators presented a complex math problem. Luo developed a staff administration system designed to efficiently allocate the pre-cleaned documents based on annotators’ preferences, expected workload, and text genres. The system estimated document difficulty and personalized document selection; it also tracked the distribution and retrieval of documents to prevent losses.
By developing a low-resource language dataset for Tibetan studies researchers, the Norbu Ketaka project has revolutionized the manual process of cleaning and annotating Tibetan texts with AI techniques and building extensive textual corpora for under-researched languages.